这次聊聊mesos+k8s的生命周期管理,包括pod、job、node等对象。
- 如果有10000台机器,你想怎么玩?(一)概述
- 如果有10000台机器,你想怎么玩?(二)高可用
- 如果有10000台机器,你想怎么玩?(三)持久化
- 如果有10000台机器,你想怎么玩?(四)监控
- 如果有10000台机器,你想怎么玩?(五)日志
- 如果有10000台机器,你想怎么玩?(六)性能
- 如果有10000台机器,你想怎么玩?(七)生命周期
- 如果有10000台机器,你想怎么玩?(八)网络
- 如果有10000台机器,你想怎么玩?(九)安全性
健康检查
一个pod在运行中,难免出现容器还好好地跑着,但是却不正常工作的情况。Kubernetes的做法是引入定时健康检查,如果健康检查失败,就把这个容器杀掉,然后kubelet就会重新启动一个容器来代替它。目前支持两种健康检查的机制:
LivenessProbe:如果健康检查失败,就把这个容器杀掉,然后kubelet根据预先设置的重启规则来决定怎么处理:啥也不干、挂了才重启或者总是重启。ReadinessProbe:如果健康检查失败,这个pod的IP地址将会从endpoints里移除,所以相当于屏蔽这个pod提供的服务而不是将它杀掉。
那健康检查怎么做呢?可以是一段脚本,返回非0就代表错误;可以说一个http请求,返回200~400之间代表成功;还可以是一个tcp端口,打开即算成功。可以通过设置kubelet的参数--sync-frequency来设置健康检查的间隔时间。还可以在设置probe的时候指定健康检查的超时时间和第一次健康检查的延时(从容器启动完毕开始)。
钩子(hook)
有时候我们需要在pod启动完成或者快要关闭的时候做点儿事情。做的事情可以是执行脚本或者发出http请求,越轻量级越好。Kubernetes提供了两个钩子来做这样的事:
- postStart:当一个容器被创建成功的时候
- preStop:当一个容器即将被关闭的时候
钩子的设计理念是“宁滥毋缺”,所以某些情况下它是有可能被执行多次的,设计自己的钩子时需要考虑这样的情况,尽量使操作“无状态”。
一次性任务
Kubernetes除了支持服务,也支持一次性任务Job。这个概念在Kubernetes 1.1版中已经有了,1.2版才算开发完成。因为一次性任务结束以后还重启没有意义,所以它不支持“总是重启”的重启规则。Job有三种类型:
- 非并行:就是启动一个pod,当pod成功结束了就算是job完成了
- 固定数量并行:并行启动固定数量个pod,每个pod都成功结束了就算是job完成了
- 工作队列并行:行启动多个pod,其中一个pod成功结束了,其他pod就开始停止运行。当全部pod都停止了就算是job完成了
其实我们当然也能不使用job这个概念而直接启动一个pod来完成我们的一次性任务。可是如果pod运行过程中那个node要是挂掉了那就糟糕了。对了,rc不就是来保证pod总是有实例在运行的机制吗?那么为啥我们还需要job这个概念呢?原来rc是为永不停止的pod设计的,而job是为需要停止的pod设计的,就这么简单。
扩容缩容
虚拟机级别上,Mesos也能轻松做到动态增删slave,从而为kubernetes提供更多的offer;与此同时,kubernetes也支持动态增删节点。容器级别上,Kubernetes的replication controller可以很容易地对pod进行扩缩容。此外,Kubernetes 1.2版正式支持HPA。大致来说,就是根据CPU的使用率来自动扩缩容。由于获取CPU使用率需要用到heapster,所以必须部署它。
值得一提的是,Kubernetes在删除pod的时候并不会把容器删除,是出于可能需要在以后查看日志的考虑。
滚动升级
Kubernetes的replication controller还支持滚动升级(rolling update)。当我们想用新版本的镜像来代替已经部署的旧容器的时候,这个特性能用类似蓝绿部署的方式帮我们轻易升级。这个方式是:创建一个副本数为1的rc并关联到新pod,逐渐增加它的副本数并减少旧rc的副本数,最终完全替代。讲起来挺生涩,其实很简单:举个栗子,有一个既存服务来自于3个pod,我们希望用新的pod来代替旧的。这是现在的情况: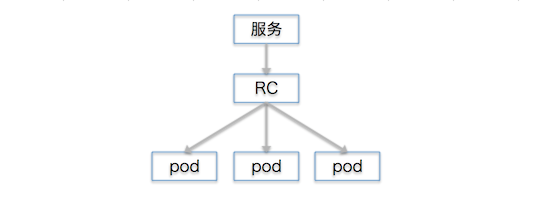
Kubernetes启动了一个新的rc,它有一个新的pod,并关联到服务上去。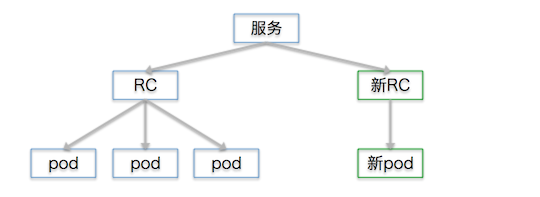
然后停掉一个旧的pod,保持这个服务的pod总数还是3个: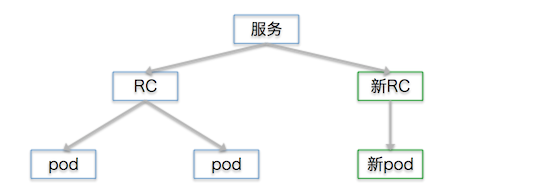
继续增加新pod: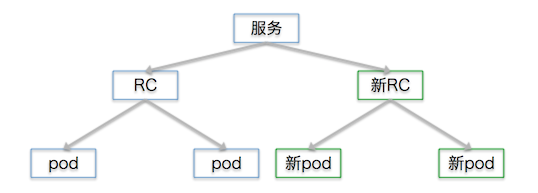
继续停掉旧pod: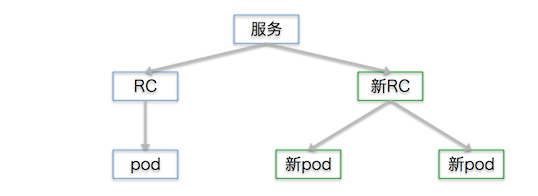
增加新pod: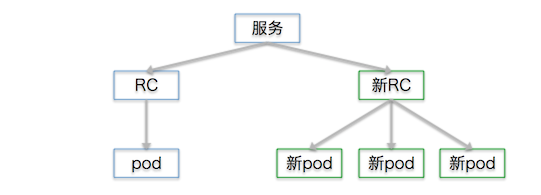
停掉旧pod,再把没用了的旧rc也删掉: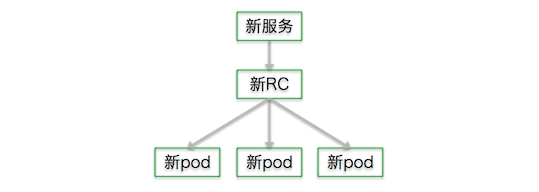
这样新服务就起来了!中间的替换速度是可以由我们设定的,还支持回滚。在这里有一个例子可供参考。