如果有10000台机器,你想怎么玩?(四)监控
这次聊聊mesos+k8s的监控告警方案。所谓监控主要就是收集和储存主机和容器的实时数据,根据运维人员的需求展示出来的过程。
- 如果有10000台机器,你想怎么玩?(一)概述
- 如果有10000台机器,你想怎么玩?(二)高可用
- 如果有10000台机器,你想怎么玩?(三)持久化
- 如果有10000台机器,你想怎么玩?(四)监控
- 如果有10000台机器,你想怎么玩?(五)日志
- 如果有10000台机器,你想怎么玩?(六)性能
- 如果有10000台机器,你想怎么玩?(七)生命周期
- 如果有10000台机器,你想怎么玩?(八)网络
- 如果有10000台机器,你想怎么玩?(九)安全性
数据采集
cAdvisor由谷歌出品,可以收集主机及容器的CPU、内存、网络和存储的各项指标。它也提供了REST API以供其他程序来收集这些指标。可以很简单地用容器将它启动起来。它提供了一个页面,通过下面这幅图可以有个直观地认识: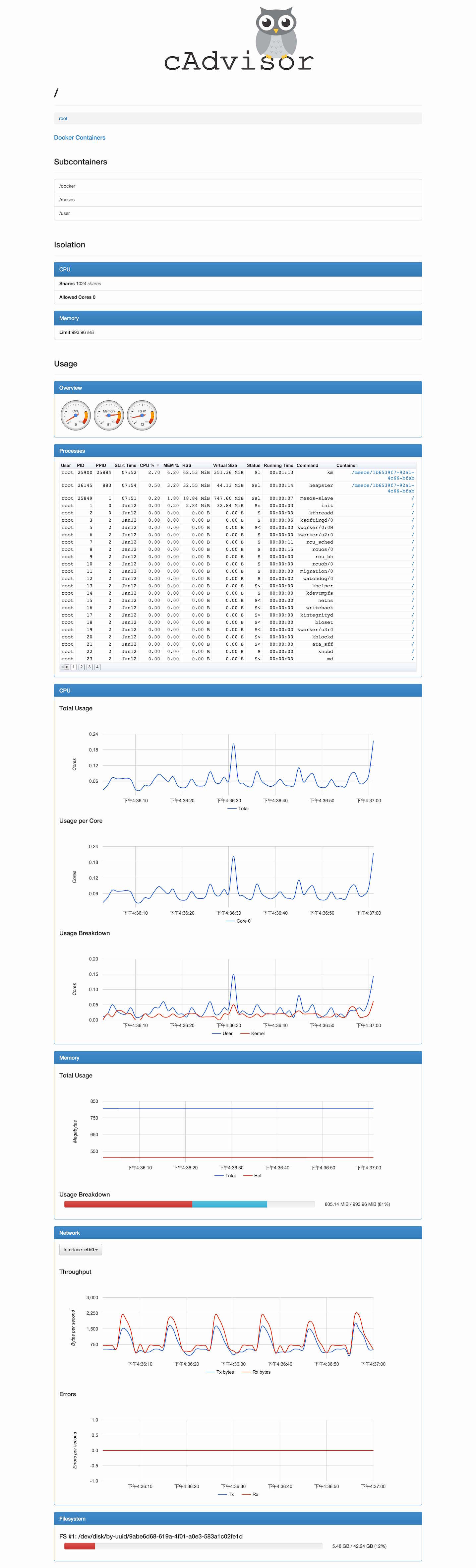
kubelet集成了cAdvisor,由于kubernetes会在每个slave上启动kubelet,所以我们不用额外运行cAdvisor容器,就能够监控所有slave的主机和容器。
从cAdvisor提供的漂亮页面上,我们能看到某台主机及其中的容器监控数据。但是还不够,我们想要的是整个集群的数据,而非一个个单体。这时候就轮到heapster出场了。它支持cAdvisor和kubernetes v1.0.6及后续的版本。运行heapster需要指定两个参数:一个是用https的方式启动的kubernetes api server用来收集数据,另一个是将收集到的数据储存起来的地方,以供随时查看。
数据存储
InfluxDB正是这样一个数据存储的地方。它是InfluxData公司开发的一个分布式键值时序数据库,也就是说,任何数据都包含时间属性。这样可以很方便地查询到某段时间内的监控数据。举个栗子,查找5分钟前的数据:WHERE time > NOW() - 5m。InfluxDB提供了前端页面供我们查找数据: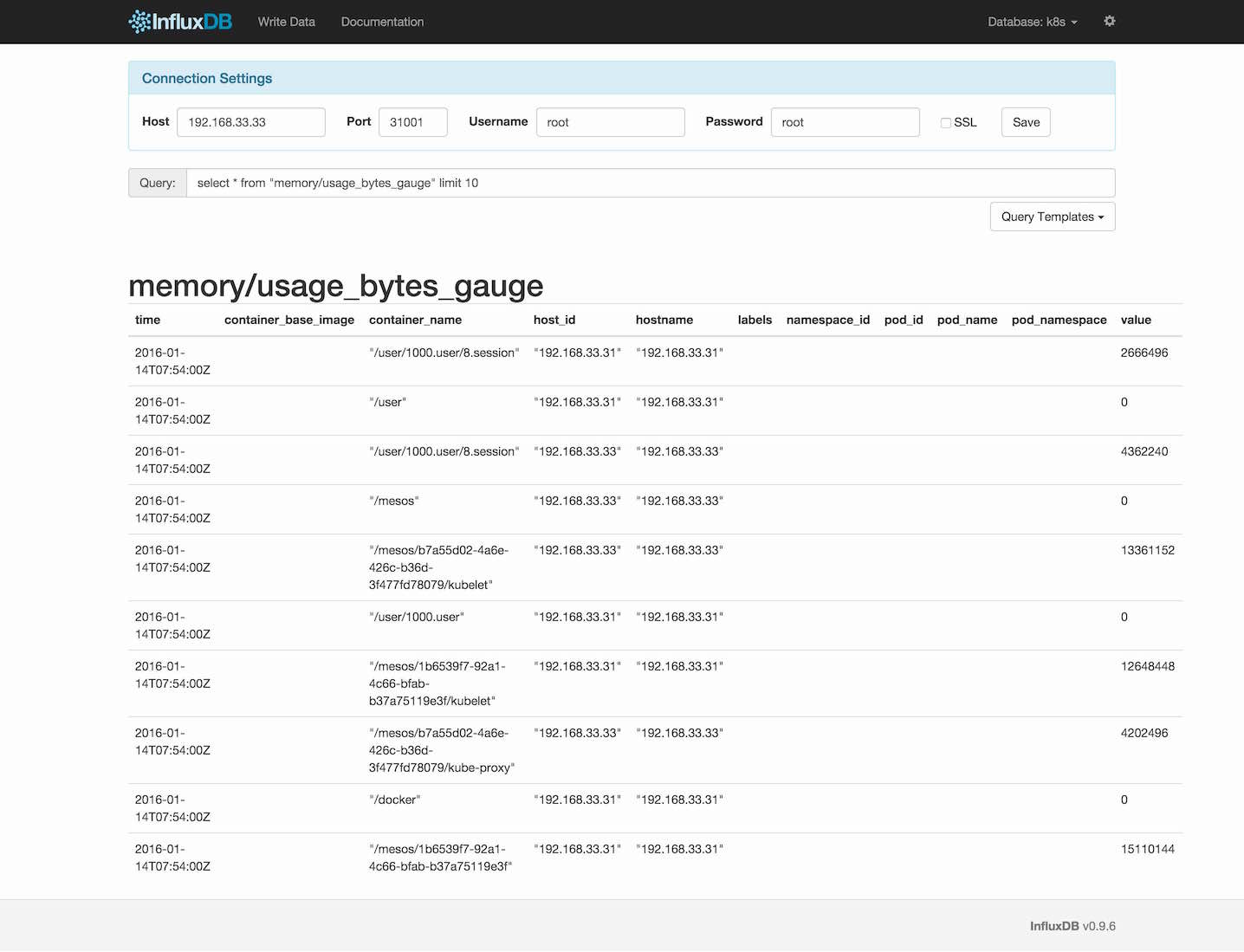
听说InfluxDB的性能一般,如果使用中遇到坑,可以试试OpenTSDB。
数据可视化
数据也都整合起来了,现在缺的是一个页面将这些数据显示出来。Grafana是纯js开发的、拥有很炫页面的,你们喜欢的Darcula风格的前端。只要指定InfluxDB的url,它就可以轻易地将数据显示出来。看看这个页面: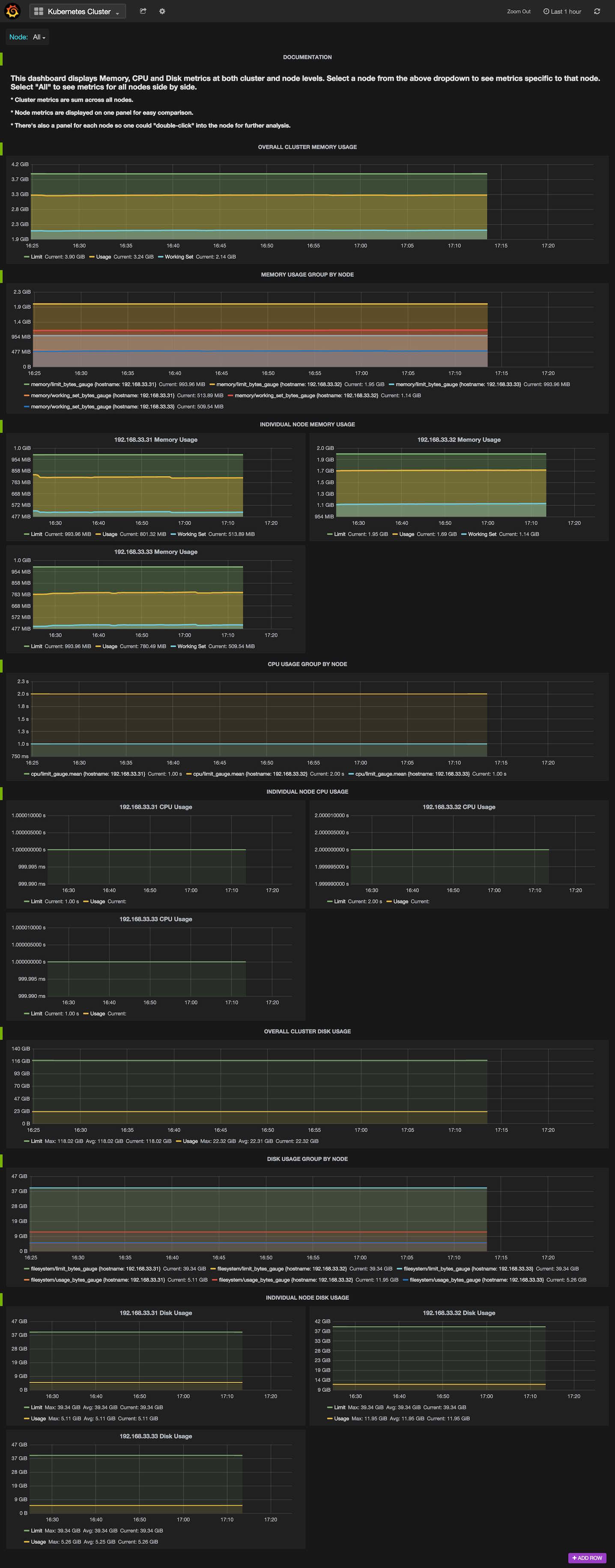
heapster的数据除了传送出去保存起来,也可以被kubedash所用。它也提供了监控信息的实时聚合页面,可是由于没有地方储存,看不了历史数据: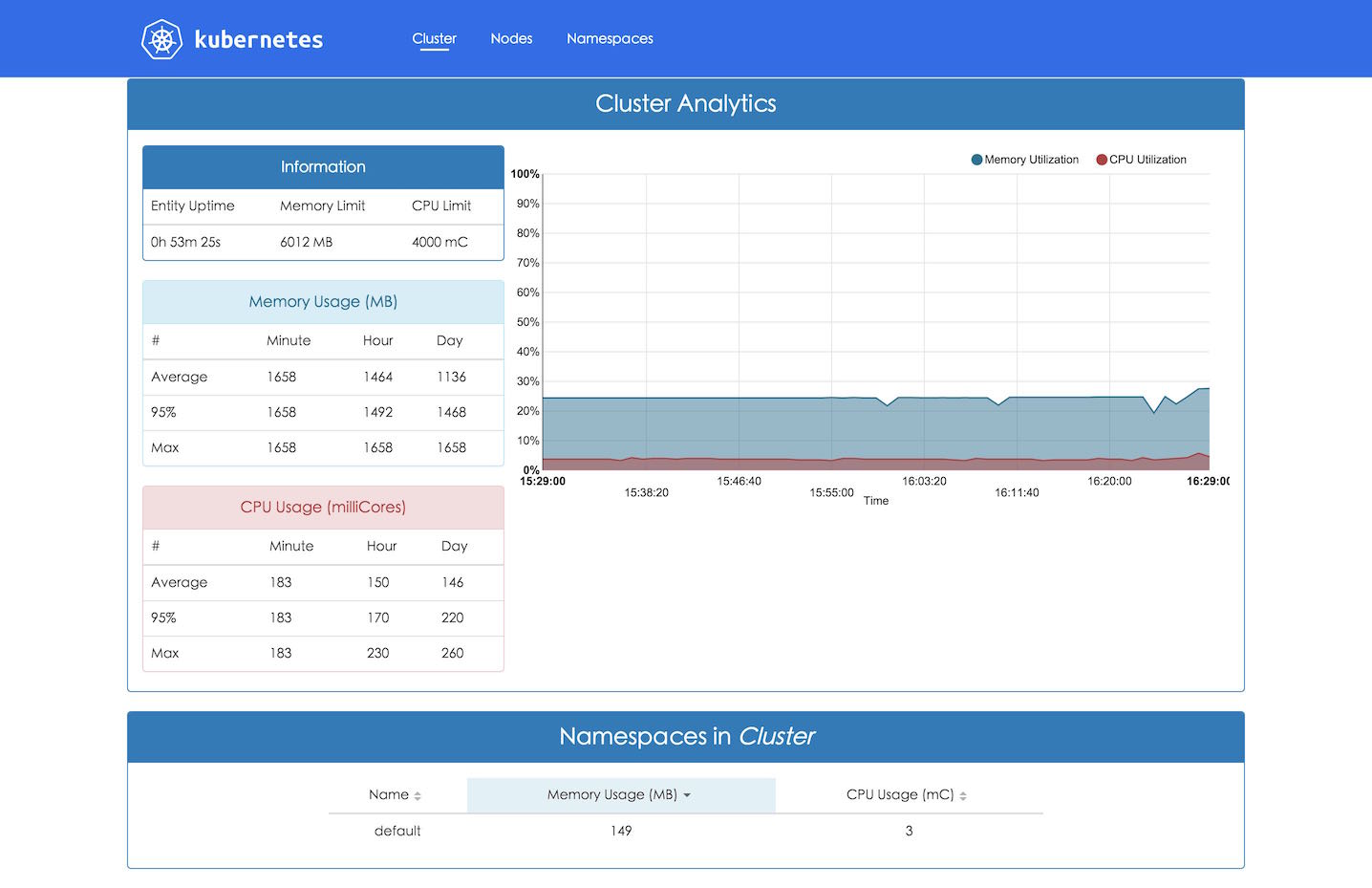
告警
InfluxData公司除了InfluxDB,还提供了一整套的TICK stack开源方案,其中的Kapacitor正是一个我们需要的告警平台。它使用叫做TICKscript的DSL,通过数据流水线来定义各种任务。通知方式除了写log、发送http请求和执行脚本,还支持Slack、PagerDuty和VictorOps。因为Kapacitor和InfluxDB都是InfluxData公司的产品,所以它们之间的无缝集成也是理所当然的。
其他解决方案
Prometheus是一个监控系统解决方案,包含了数据采集、时序数据库、UI可视化、告警等诸多功能。它的特点是可以实现多纬度的监控,在对比不同实例的监控数据图上有优势。它还有许多的exporter可以很方便地从许多第三方应用中导出数据,如Apache、AWS、Redis等,也支持Mesos、Kubernetes和Kubernetes-Mesos。可以参考《用容器轻松搭建Prometheus运行环境》来自己搭建一个测试环境。
