Apache Solr是用Java开发的基于Apache Lucene的高性能全文检索服务器,可以运行在web容器里,提供搜索引擎服务。本文旨在用docker来快速入门并尝试Solr提供的各种功能。
对Elasticsearch入门有兴趣的朋友请参考用容器快速上手Elasticsearch。
启动
关于Solr的入门知识,有一本gitbook:《用Solr构建垂直搜索引擎》写得不错。本文关心的是实际操作,所以这就开始吧。通过docker,一条命令就可以直接启动Solr:
1 | docker run -d -p 8983:8983 --name solr solr:6.1.0 |
我用的是mac,通过docker-machine env default命令可以看到默认的default docker-machine的IP地址是192.168.99.100,于是便可以通过http://192.168.99.100:8983/solr来访问Solr Admin了:
在Solr里,Core可以认为是一个集合,一个Solr实例可以有多个Core。可以说Solr实例和Core的关系像是数据库实例和数据库的关系。现在我们来新建一个core,命名为ggg:
1 | docker exec -it --user=solr solr bin/solr create_core -c ggg |
索引
Solr支持xml、json和csv格式的数据文件用于索引。接下来让我们来试试。首先登录进solr容器:
1 | docker exec -it --user=solr solr bash |
xml
Solr存储的对象称为Document,每个Document数个Field组成,每个Field代表一个属性。现在按照<add><doc><field name="">的格式来生成一个xml文件:
1 | cat books.xml |
细心的你可能已经发现了下面一条数据里并没有fantasy,我故意的~~现在用以下命令将这个xml导入索引:
1 | bin/post -c ggg books.xml |
索引完成后,在Solr Admin的ggg Core的Query里,直接点击Execute Query便可以看到我们新索引的这两条数据: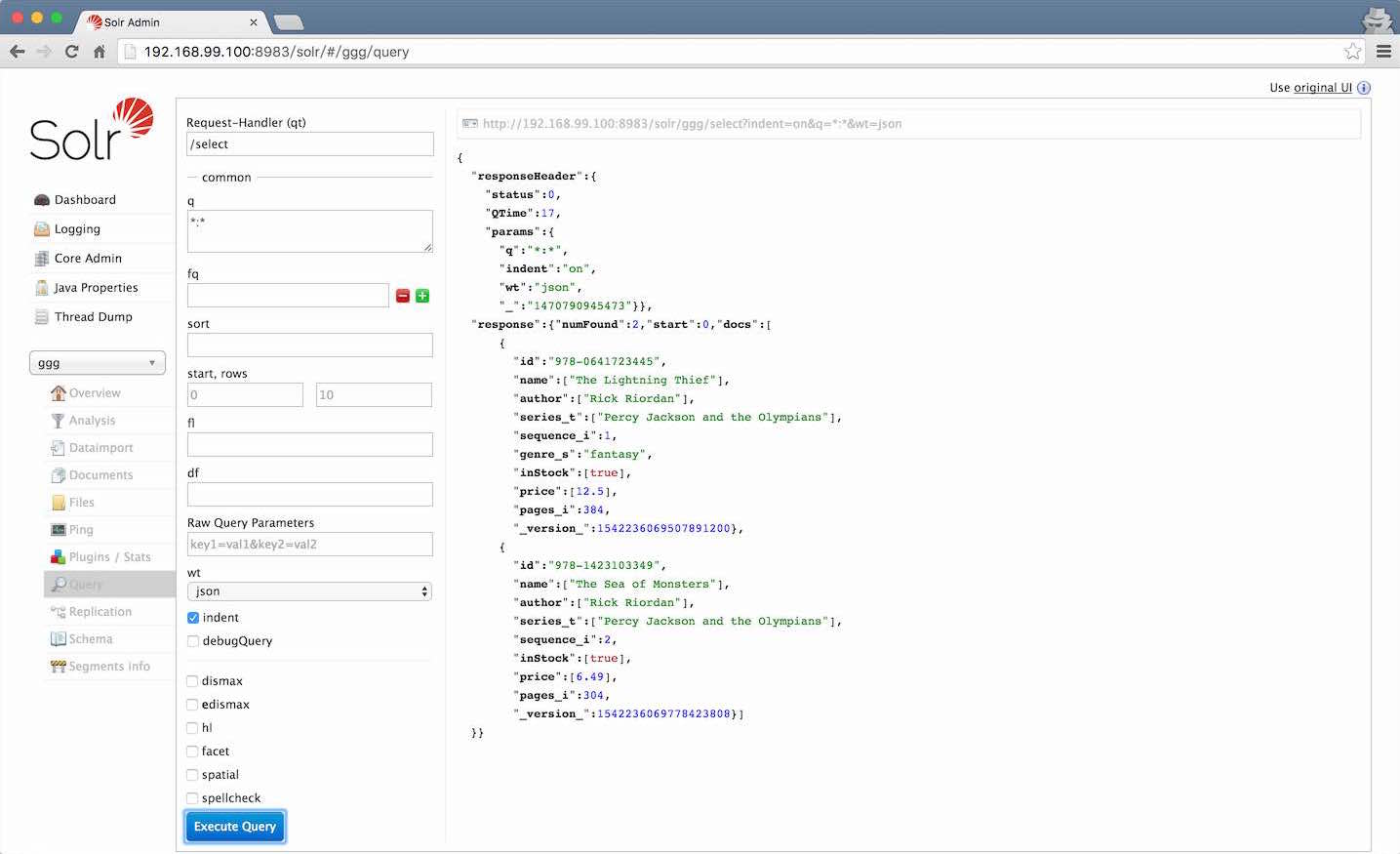
在q里输入搜索的关键词便可以查询索引:
- Rick Riordan:匹配作者
- Jackson:分词可以工作
- the:不区分大小写
- fantasy:不符合的记录不会被查询到
- fantasy 0123:不是所有关键词都会被使用
- 0123:但如果只有查不到的关键词,那就是查不到
- fantasy -Rick:
-表示过滤 - Lightni:单词不全不能匹配
- Lightn?ng:
?匹配一位 - L*g:
*匹配多位 - Lightnixx
:``用于模糊查询 - Lightnxxx
:``最多就匹配两位
还有很多查询的技巧,可以在这里找到。
再次导入相同的数据:
1 | bin/post -c ggg books.xml |
可以看到查询结果并没有变化。这是因为solr会根据id来区分每一个数据。如果更新xml再导入,那就会覆盖掉旧的数据。现在让我们把漏了的fantasy补上:
1 | sed -i '/2/a \ \ \ \ fantasy' books.xml |
可以查询fantasy看到结果变成了两条。
json
接下来创建一个json文件并索引:
1 | cat books.json |
查询一下978,就能看到json文件的内容也被索引进来了。
csv
接下来创建一个csv文件并索引:
1 | cat books.csv |
查询一下*:*,就能看到csv文件的内容也被索引进来了。一共有14条numFound记录,但是只会显示10条。通过Query页面上的start, rows,就可以很方便地查询分页。
其它
bin/post这个命令也能索引文件夹,不管里面的文件是什么格式:
1 | mkdir books |
还有一个比较基本的需求是使用The Data Import Handler (DIH)来索引数据库。可以参考https://cwiki.apache.org/confluence/display/solr/Uploading+Structured+Data+Store+Data+with+the+Data+Import+Handler。
再有就是如何在程序中更新数据。Solr支持多种语言的客户端,对于Java来说,可以参考SolrJ。
还可以通过http请求来更新索引:
1 | curl 'http://192.168.99.100:8983/solr/ggg/update?commit=true' \ |
删除索引:
1 | bin/post -c ggg -d "12345" |
查询
其实上一节已经介绍了不少查询相关的内容了。在查询页面的右上角有一个url,例如http://192.168.99.100:8983/solr/ggg/select?indent=on&q=:&wt=json。只要对其发出get请求,便可以获取到查询结果。当然直接curl也可以:
1 | curl 'http://192.168.99.100:8983/solr/ggg/select?indent=on&q=*:*&wt=json' |
至于Query页面上的其它查询条件,可以在http://wiki.apache.org/solr/CommonQueryParameters上查到。这里简介如下:
- fq(Filter Query):过滤查询,可以指定多个条件并缓存。例如:
inStock:false - sort:排序。例如:
sequence_i desc - start:查询结果忽略掉前n条
- rows:查询结果数量
- fl(Field List):指定查询结果字段。例如
author, sequence_i - df(Default Field):指定查询字段。
- wt(Write Type):指定输出格式,有xml,json,python,ruby,php,csv等多项可选
还有一些高级功能,本文旨在入门,就不细说了。访问http://192.168.99.100:8983/solr/ggg/browse可以查看已索引的所有数据。最后输入exit退出solr容器。
中文
在没有使用任何中文分词组件的情况下,Solr会把所有中文的每个字当成一个词来检索。要想让Solr支持中文分词,需要使用中文分词组件。《与Lucene 4.10配合的中文分词比较》一文里介绍了几种中文分词组件并做了比较。虽然我们用的是Solr 6.1.0版,但是也是很有参考意义的。接下来我们使用mmseg4j来试一下。
目前的mmseg4j暂时不支持solr 6.1.0,不过已经有热心人士提交pull request了,只是还没合并进去。我们本着简单的原则,替换solr镜像成5.3.1版本。在作者的github上指定的百度网盘里下载mmseg4j-solr-2.3.0-with-mmseg4j-core.zip,解压后得到两个jar文件。之后重新创建一个solr容器并再次生成ggg的core:
1 | docker rm -f solr |
现在用solr提供的Schema API来配置mmseg4j:
1 | docker exec -it --user=solr solr bash |
上面的命令增加了textComplex和textMaxWord两种字段类型,它们的区别在这里解释得很清楚。下面就可以在Analysis页面上,看到我们的分词生效了: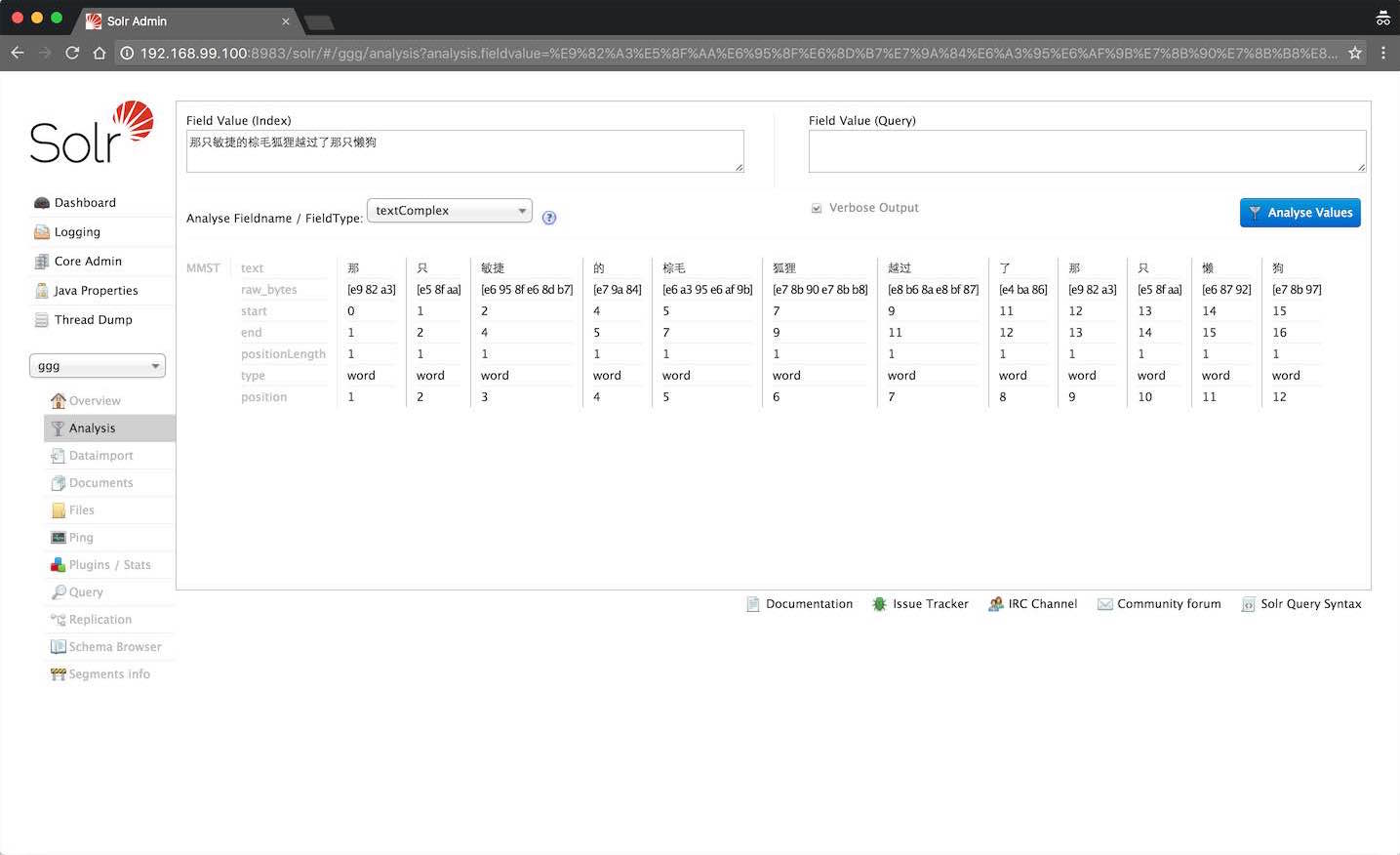
还可以尝试用孙悟空吃香蕉这个短句来测试textComplex和textMaxWord的不同效果。接下来将field desc添加到textComplex里:
1 | curl -X POST -H 'Content-type:application/json' --data-binary '{ |
现在让我们来索引几条包含field desc的中文数据:
1 | cat cities.csv |
现在在Query页面上,输入desc:中华人民共和国就可以找到相对应的记录,而输入desc:人民就已经不能检索到结果啦。