为什么
首先假定一个场景:我需要定期抓取亚马逊某商品的价格,并通知自己。传统的实现方式就是写一个爬虫,然后在服务器上cron一下就好了。虽然能使,但是一旦考虑到灵活性(商品应该可定制,通知手段应该灵活)、高可用(服务器挂了也不应该影响到业务)、可视化(提供易于使用的界面,以看当前和历史的执行情况)、可监控(看当前的执行情况、出错了需要通知开发者)等,那就费时费力了。好在AWS给我们提供了一系列的服务,允许我们像Linux的管道那样把服务简单、灵活地拼接起来,从而实现需求。
怎么用
服务介绍
首先简单介绍一下在这个工作流中我们会涉及到的AWS服务:
Step Functions:用于可视化管理工作流。是本文的核心。
SNS:通知服务,只要给主题(Topic)发消息,主题的订阅者(Subscription)就会通过订阅的渠道(如邮件、短信等)收到消息。
Lambda:无需服务器即可运行代码的计算服务,免去了管理服务器的烦恼。只有在程序运行的时候才收费。
CloudWatch:监控或触发AWS资源的服务。在本文中我们姑且把它当做一个cron服务。
Step Functions
对于本文的需求来说,最简单明了的工作流即是下图: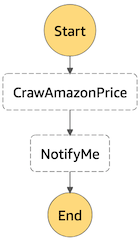
非常直观,一眼就能看出来它会先抓取亚马逊的价格,然后通知自己。对于Step Functions来说,这张流程图的代码很简洁:
Lambda
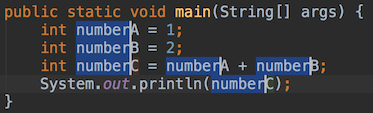
上面的CrawAmazonPrice指定了Resource是一个名为CrawAmazonPrice的AWS Lambda函数,而NotifyMe则指定了一个名为PriceDown的SNS主题。对这个主题感兴趣的用户(比如说,我)可以用期待的方式(邮件、短信等)订阅它。所以这个流程就是:开始->CrawAmazonPrice(Lambda)->NotifyMe(SNS)->结束。
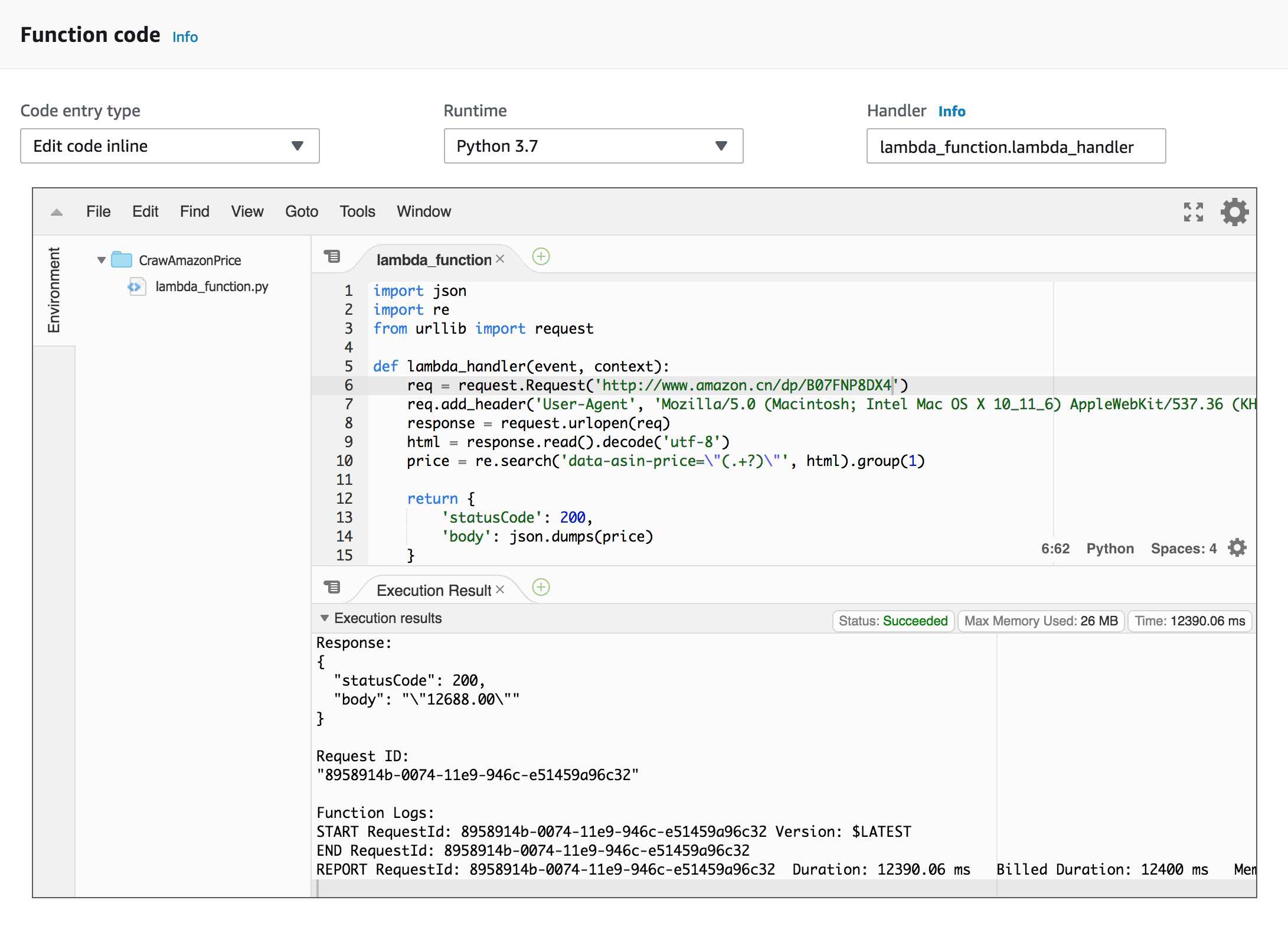
为了简便起见,我们可以直接通过AWS界面实现CrawAmazonPrice的Lambda函数。直接新建一个Python 3.7的脚本即可:
SNS
SNS就更简单了,创建一个名为PriceDown的新主题,然后为它创建一个协议为Email的订阅,填入自己的邮箱地址,便会收到AWS给这个邮箱发送的确认订阅邮件。点击邮件中的链接,即可完成订阅。要是日后有其他人对这个主题也感兴趣,增加一个订阅即可。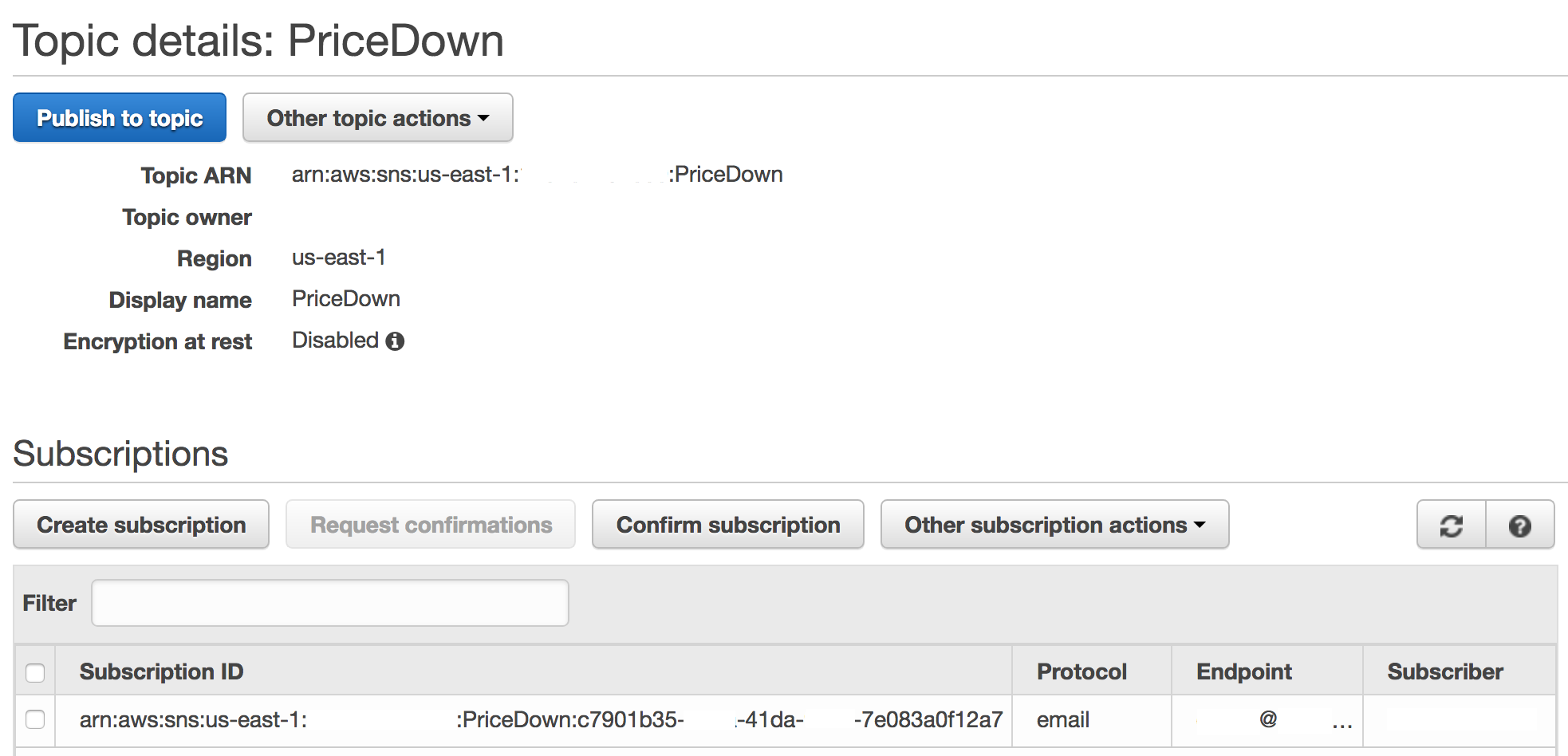
CloudWatch
剩下的事情就是创建一个CloudWatch,来定期触发这个Step Functions。直接通过AWS界面创建一个规则(Rule),固定频率为每天,将目标设置为上面的Step Function工作流,取个名字如DailyLookUpPrice就可以啦!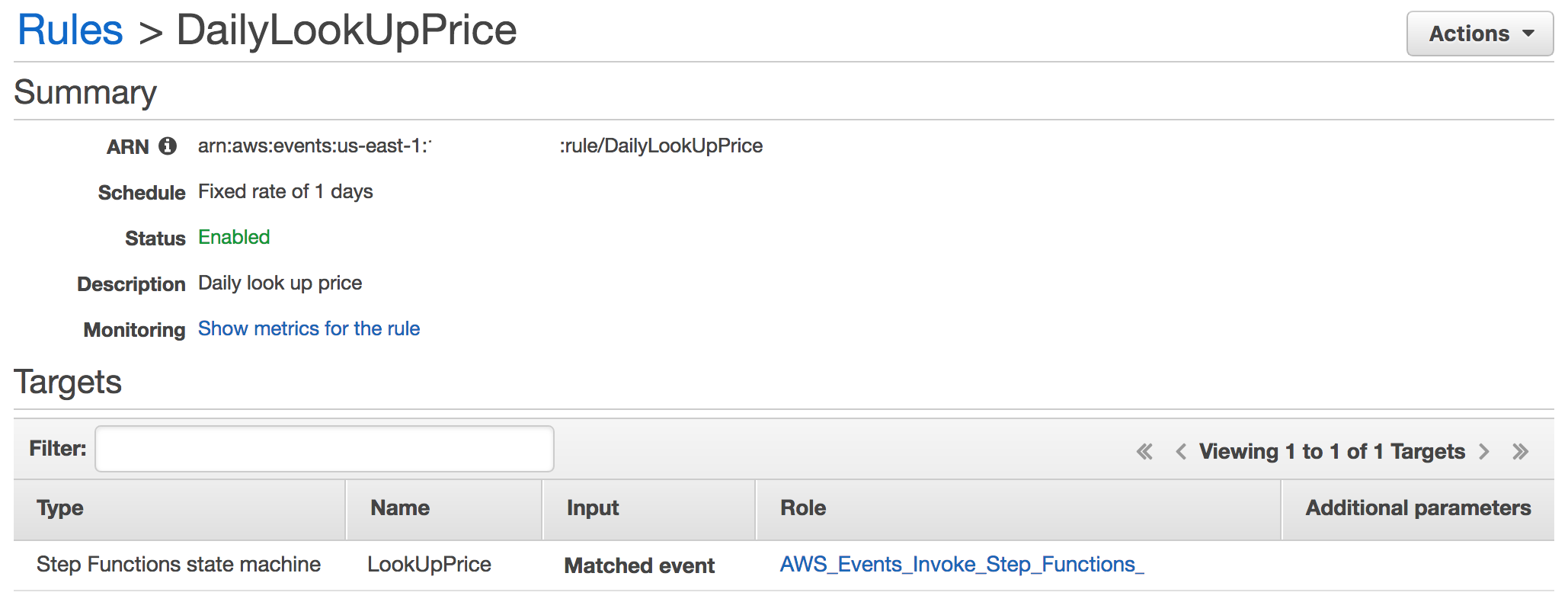
执行
每次当CloudWatch被触发时,都会在Step Functions中留下自己的足迹。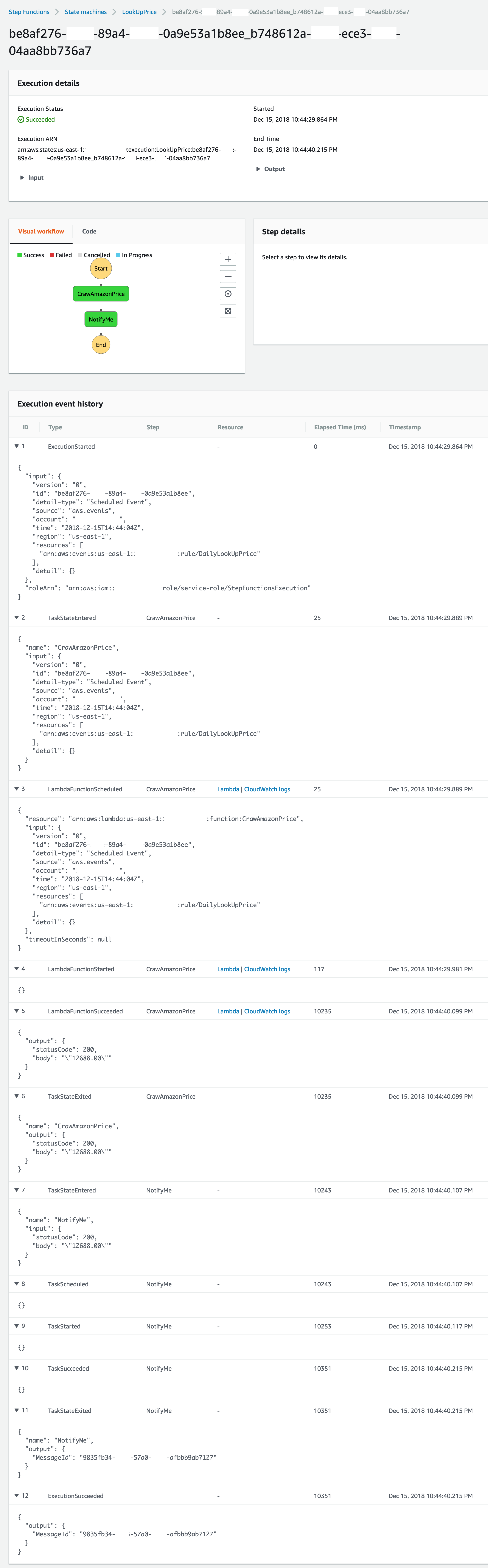
由上图可以看到,每个状态的进入和退出都清晰可见,非常方便。
需求变更
假如我们只想在价格低的时候通知自己,除了修改Lambda中定义的代码以外,还可以增加一个Task,以便增强灵活性。例如,公司内部有一个最低价格的服务,但是无法被公司外部(如AWS)调用到。即便如此,Step Functions也可以支持这种应用场景。在任何可以调用公司服务的地方写一段代码,这段代码作为一个活动(Activity)来轮询Step Functions,当执行到该Task时,该代码就被运行,调用公司内部的服务。AWS的实现也很简单,首先新增一个名为EnsureLowestPrice的活动,然后在Step Function的JSON中增加一个Task,并修改CrawAmazonPrice,使其Next指向EnsureLowestPrice:
这回的Task就不是Lambda啦,而是自己运行在随意机器上的代码。以Java为例,可以参考AWS官方文档来实现。
“价格低于最低价”的服务,在这里只是一个表示内部服务的示例罢了。当然,如果真要实现一个类似的服务,用AWS的DynamoDB甚至S3可以很方便地实现。
假如需要并行查询多种商品价格,Step Functions也能轻易支持: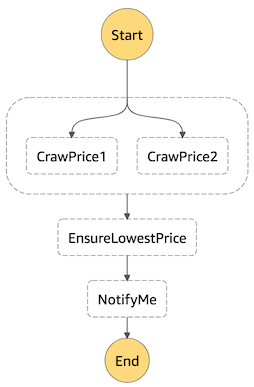
并行的代码如下:
由于Branches及States的灵活性,再复杂的工作流也不在话下。
进阶功能
超时
如果代码出现死循环之类的问题,可能会导致工作流无法继续流动下去。这时可以通过给该状态设置超时TimeoutSeconds以使之到时退出。合理地设置这个值需要考虑某个状态可能需要运行的时间、是否有人工步骤等。默认的TimeoutSeconds为99999999。
心跳
如果程序可能运行数个小时,也许你难以知道现在的状态是运行中,还是程序挂掉了。这时可以通过设置心跳HeartbeatSeconds来使Step Functions知道当前的运行状况,以便及时把挂掉了(没有心跳了)的任务分发给其它节点。当然为了这个功能,程序中需要增加相对应的逻辑(定期发送心跳)。
重试
有时候程序出错,可能只需要重试一下就好了。这时我们可以使用Step Functions提供的重试Retry机制。如以下程序所示:
Retry是一个集合,所以可以为不同的错误定义不同的重试机制。
异常处理
如果重试还是不行,那还有一个招式就是异常处理机制Catch。它与重试类似,可以为不同的错误定义不同的状态流向:
在上面的代码里,只要出错了(并且重试也没有成功),就跳转到NotifyError的状态,可以通过SNS通知订阅者了。
错误状态
在异常处理中由于跳转到了NotifyError,并且通知成功,反而倒让这个工作流从异常变成正常了。想让工作流失败,只需在NotifyError的后面接一步简单的FailExecution状态就可以了。
最终工作流
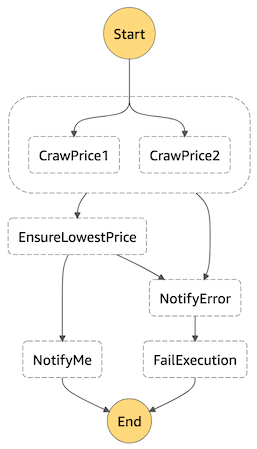
其它
最求完美,永无止境。例如,这些服务我们现在都是在AWS界面上点来点去的,其实这些人工操作可以通过CloudFormation来变成自动化的脚本。如此,便可以实现我们的基础设施即代码,做到一键部署了。另外,随着需求的演化,如果要更新Step Functions的工作流,还可能需要考虑到对其进行版本管理。还有,当处理活动的节点数较多时,如果能够把某次执行的机器名输出到工作流中,也有助于错误排查。