这次聊聊mesos+k8s的性能。纯粹的kubernetes v1.1可以支持250个节点,但是一跟mesos结合起来,由于需要等待、接受资源邀约等行为,确实会更慢一些。
- 如果有10000台机器,你想怎么玩?(一)概述
- 如果有10000台机器,你想怎么玩?(二)高可用
- 如果有10000台机器,你想怎么玩?(三)持久化
- 如果有10000台机器,你想怎么玩?(四)监控
- 如果有10000台机器,你想怎么玩?(五)日志
- 如果有10000台机器,你想怎么玩?(六)性能
- 如果有10000台机器,你想怎么玩?(七)生命周期
- 如果有10000台机器,你想怎么玩?(八)网络
- 如果有10000台机器,你想怎么玩?(九)安全性
关于性能
有一篇很知名的kubernetes性能测试文章,提到了不少性能测试的考量、结果和计划,也有中文译文。相信看完后对kubernetes自身的性能会有一些感性认识。
Kubernetes v1.0仅仅支持100个节点,kubernetes v1.1已经可以支持250个节点了。官方也希望能在2016年初支持1000个节点。Kubernetes还提供了一个性能测试工具Kubemark。它由真实的master和虚拟的空节点组成,默认跑在GCE上,这样不需要大量机器便可以进行性能测试了。
注意事项
根据kubernetes大集群这篇文章的描述,1.1版本支持最大250个节点,每个节点30个pod,每个pod 1~2个容器。当使用50台以上的节点时,最好用单独的etcd来存储事件。可以在kubernetes的api server启动参数里配置类似--etcd-servers-overrides=/events#http://192.168.33.11:4001这样的值来分离事件etcd。
如果想尽可能的模拟生产环境,所以在测试环境中使用kubernetes自身的系统插件(如DNS、Heapster、ElasticSearch等)时,也需要注意由于集群规模的增大,默认的插件资源有可能不够,从而导致OOM最终使插件不停地挂掉重启。可以通过配置resources的limit来增大插件的内存供给。
Docker的性能方面,由于Ubuntu的docker存储驱动默认使用AUFS,速度比Device Mapper快上不少。所以如果用CentOS来做node,会明显感觉容器的启动删除都比较慢。网上也有文章指出这点,笔者测试的感觉与之相符。
性能调优
Mesos+Kubernetes
Mesos的资源分配现在是酱紫的:
- slave告诉master自己有什么资源
- master把这个资源包装成offer发送给framework(这里是kubernetes)
- framework接受或拒绝
- 若是framework接受了,让slave运行任务
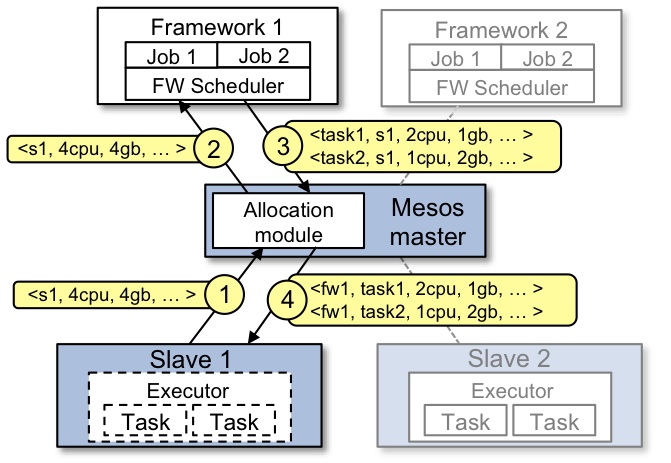
有一点需要注意的是mesos master并不是一收到slave的资源便把它发送给framework的。想象一下如果有1000台机器的话,那offer的发送频率得是什么样子。Mesos master是每隔一段时间发送一次。它的启动参数里有一个--allocation_interval,它决定了这个间隔时间,默认为1秒。当有多个slave的时候,有可能master在前一秒告诉framework有10份offer,后一秒又告诉说现在有15份(有些被拒绝的offer回来了,有些新slave能提供新offer,有些被接受了,但是还有余裕…)。
Mesos+Kubernetes的分配算法现在还很原始:一个offer只会运行一个pod。所以如果请求启动的大量的pod的时候,就需要很多个offer来运行这些pod。为了提高性能,一个办法是在一个offer里安排多个pods,这个是kubernetes的未来计划,现在还不是我们的菜。另一个办法是提高mesos master的offer频率。虽然把--allocation_interval调低可以增加offer发送频率,但是如果offer回流得很慢,那又有什么意义呢。所以kubernetes的scheduler处理得越久,offer的流动性就越差,pod的启动速度就越慢。接着往下走,如何提高scheduler的处理速度呢?最简单的处理办法:换高配!4C8G的虚拟机撑死能扛住250台mesos slave。软件上就还得靠优化scheduler的流程了。另外,mesos master由于要不断发offer出去,还要处理被接受或拒绝的offer,也需要比较强的配置,但是kubernetes master的配置影响力更大,需要相对更好的配置。
Mesos+Kubernetes的scheduler还支持一些细粒度的性能调优,有兴趣的朋友可以去看一看。
纯kubernetes
不带mesos玩儿的kubernetes会简单一些,它的scheduler支持一个参数--bind-pods-qps,这个值决定每秒启动的pod数,默认为50。可以根据机器和网络性能相对应地调节。
测试结果
Mesos+Kubernetes
Mesos+Kubernetes的情况下,100台mesos slave的情况下,启动100个pod需要将近50秒。由上可知,由于offer是比较均匀的,pod的创建时间基本上也是均匀的。这就意味着启动500个pod需要将近250秒。而且,pod还是比较平均地分布在所有slave上的。删除pod的话,因为无关offer,所以就不是线性关系了。100个pod需要10~15秒,如果一口气删得多一些,需要的时间会比线性增加的时间少一些。250台mesos slave的情况下,基本上kubernetes就带不动了,api server的cpu占用率很高。
纯kubernetes
不带mesos玩儿的kubernetes在100台节点的情况下,速度要快得多:启动100个pod仅需10秒左右,1000个约80秒。如果分配超过3000的pod,就会出现部分pod起不来的情况。笔者试验了4000个pod,有280个起不来。250台节点的时候也没有什么压力,性能上比Mesos+Kubernetes好了不止一星半点。现在kubernetes 1.2版已经发布,支持1000个node不成问题。就是…如果按本文的标题来说,10000台机器,还是得建10个kubernetes集群才行呀。