如果有10000台机器,你想怎么玩?(一)概述
这一系列文章主要是关于kubernetes和mesos集群管理的内容,里面不会说用啥命令,怎么操作,而是了解一些基本概念,理清思路。如果你需要的是实操,请参考《轻松搭建Kubernetes 1.2版运行环境》。
本系列目前有九篇:
- 如果有10000台机器,你想怎么玩?(一)概述
- 如果有10000台机器,你想怎么玩?(二)高可用
- 如果有10000台机器,你想怎么玩?(三)持久化
- 如果有10000台机器,你想怎么玩?(四)监控
- 如果有10000台机器,你想怎么玩?(五)日志
- 如果有10000台机器,你想怎么玩?(六)性能
- 如果有10000台机器,你想怎么玩?(七)生命周期
- 如果有10000台机器,你想怎么玩?(八)网络
- 如果有10000台机器,你想怎么玩?(九)安全性
少年,10000台机器只是哄你进来看看而已。这是个虚数,想做的事情其实是:我有那么几台虚拟机,要对外提供容器化PaaS服务,你想怎么玩?
不管这些机器是虚拟还是实体,是啥操作系统,实际上我拥有的是一堆的资源,如cpu、内存、硬盘等。当有人需要某个服务的时候,我从这堆资源中启动某个服务给对方即可。在单机环境中,操作系统有能力帮我们做这样的事情。当我们需要一个服务时,我们就启动一个应用,这个应用使用了操作系统的一些资源,为我们提供服务。剩下的资源可以为我们提供其他的服务。在集群环境中,mesos有能力帮我们做这样的事情。它就像一个操作系统,告诉我们现在集群中有多少的资源。当我们需要一个服务时,我们就启动一个任务,这个任务使用了集群环境的一些资源,为我们提供服务。剩下的资源可以为我们提供其他的服务。一般情况下我们看到的mesos主页是这样子滴: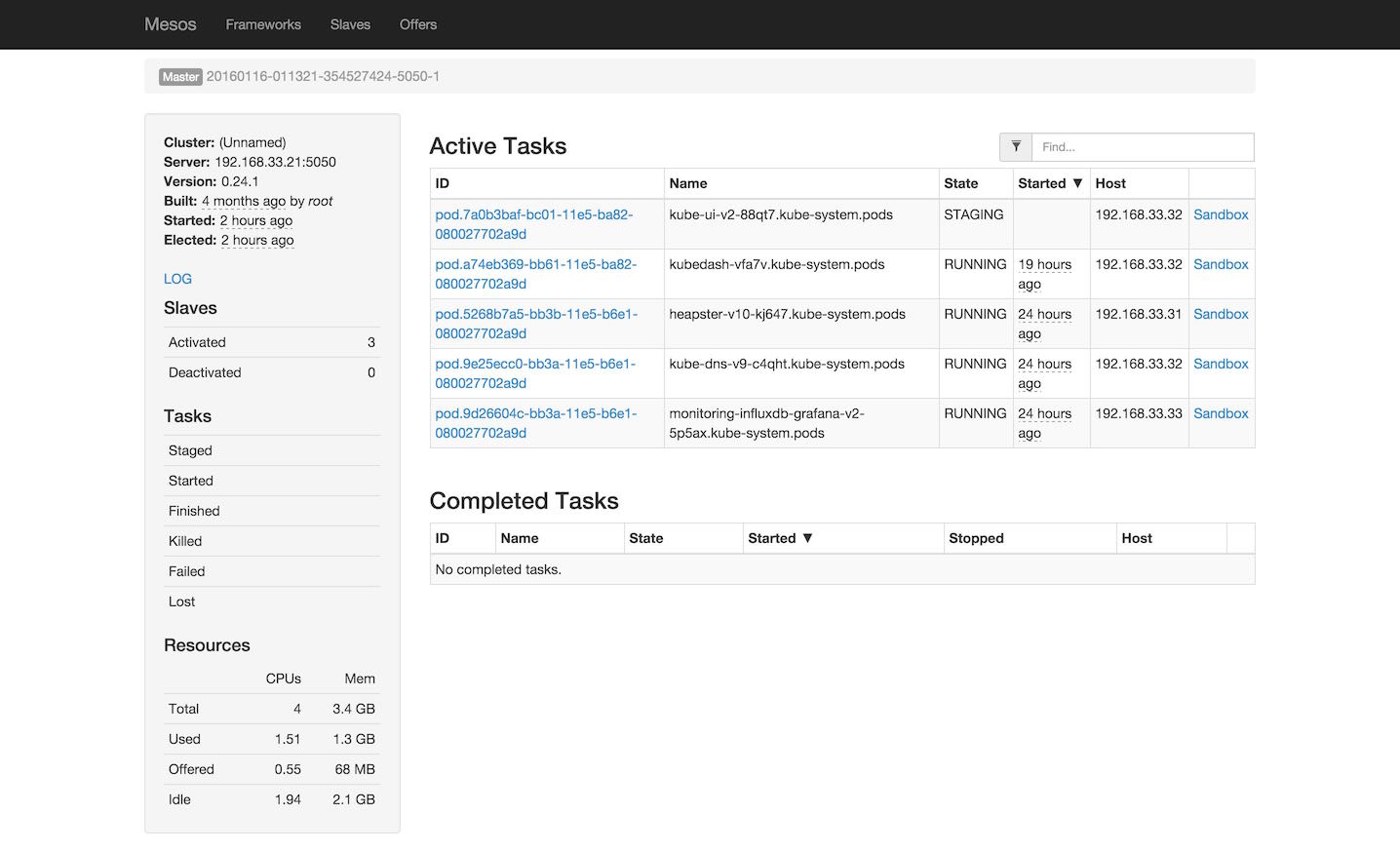
我们不希望各个任务太不一样,因为那管理起来很麻烦。神一般的docker把各种任务都抽象成一个容器,这样启动一个任务就变成启动一个容器了,大大解放了我们的双手,让我还有时间在这里码码字。尽管如此,我们还是需要管理我们的容器。Kubernetes就是这样一个容器编排工具。大家叫它k8s,听起来就像i18n那么的亲切。它有自己的一些概念:首先是pod,它里头可以含着多个容器的实例,是k8s调度的原子单元。其次是Replication Controller简称rc,它关联一个pod和一个pod数量。最后是service,它通过rc暴露出来。这三个概念听起来没啥,混合起来使用威力十足。举个栗子:pod里面有一个nginx容器,有一个rc关联到这个pod,并暴露出服务以使外界可以访问这个nginx。当访问量很大的时候,运维人员可以把rc的pod数量这个值从1调整成10,k8s会自动把pod变成10份,从而让nginx容器也启动10份,而服务则会自动在这10份pod中做负载均衡(截稿为止,这个负载均衡的算法是随机)。一条命令就能轻易实现扩容,当然前提是mesos那头有足够的资源。Kubernetes有一个kube-ui的插件可以可视化当前的主机、资源、pod、rc、服务等: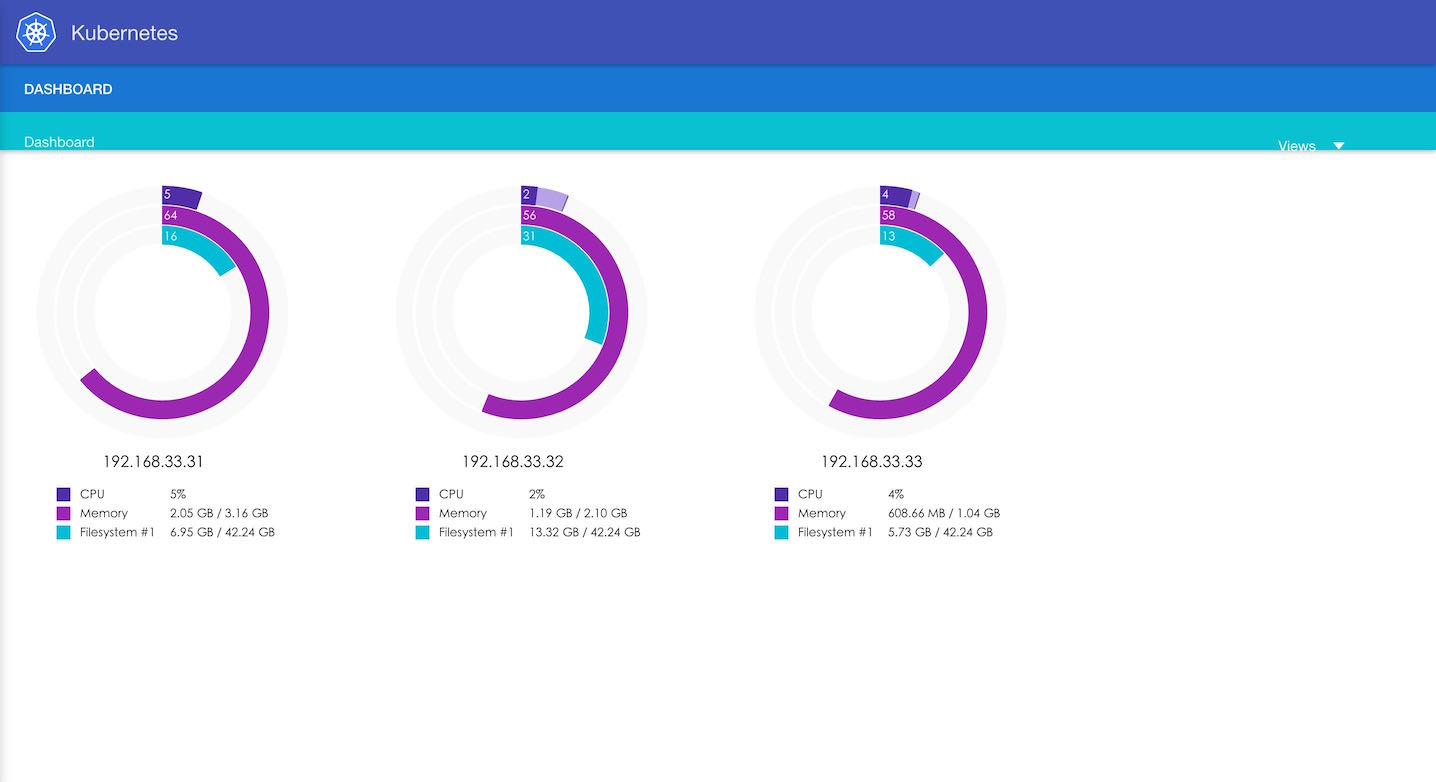
集群操作系统和容器编排工具都有了,假设我们需要一个mysql服务。用k8s启动一个docker hub下的官方镜像,于是它就会被mesos分配在某台有资源的机器上。用户并不关心到底被分配到哪台机器上,只关心服务能不能用,好不好用。现在问题来了:要是服务挂掉,数据会不会丢失?那么应该怎么做持久化?这里需要引入k8s的另外两个概念:PersistentVolume(PV)和PersistentVolumeClaim(PVC)。简单说来,PV就是存储资源,它表示一块存储区域。比如:nfs上的、可读写的、10G空间。PVC就是对PV的请求,比如需要–可读写的1G空间。我们的mysql直接挂载在需要的PVC上就可以了,k8s自己会帮这个PVC寻找适配的PV。就算mysql挂掉或者是被停掉不用了,PVC仍然存在并可被其他pod使用,数据不会丢失。
现在数据库也有了,需要一个tomcat服务来使用刚才创建的mysql服务并把自己暴露到公网上。传统上说,要使用数据库那就得在自己应用的xml或config文件中配置一下数据库的链接,java平台上一般是酱紫滴:jdbc:mysql://localhost:3306/dbname。可是mysql服务并不在localhost上,我们也不知道它被分配到哪台机器上去了,怎么写这个链接呢?这里边就涉及到k8s服务发现的概念了。一种方法是,k8s在新启动一个pod的时候,会把当前所有的服务都写到这个pod的容器的环境变量里去。于是就可以使用环境变量来“发现”这个服务。但是这种做法并不推荐,因为它要求在启动pod的时候,它所需要的服务已经存在。是啊,如果服务不存在,怎么知道往环境变量写什么呢?由于环境变量大法严重依赖于启动顺序,所以一般使用DNS大法。k8s提供了kube2sky和skydns的插件,当mysql服务启动后,这哥俩就会监听到mysql服务,并为之提供dns服务。所以只要配置成jdbc:mysql://mysql.default.svc.cluster.local:3306/dbname便可以解决服务发现的问题了。
接着往下走,还会涉及到外部负载均衡、高可用、多租户、监控、安全等一系列挑战,你想怎么玩?
