程序员常见的编码和转义
作为一名天朝程序员,除了看惯了乱码之外,在日常的工作中经常会碰到编码和转义。如果能掌握这块领域的一些常识,就可以在开发和支持时游刃有余。
编码(encoding)
ASCII & EASCII & ISO-8859-1
要聊编码,就需要从ASCII开始。众所周知,计算机的世界里,数据都是0和1这样的二进制。用它们的组合来表示字母、数字和常用符号的最通用编码标准就是ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)。完整的ASCII编码可以从这里找到。Mac或Linux可以用以下命令来查看所有的ASCII字符:
其中,00000000到00011111的前32位字符和01111111是控制字符,00100000到01111110之间的都是可显示字符,一个字符占8位(bit),第1位总是0,这样能够支持2的7次方即128个符号编码。虽然ASCII编码能搞定美国大多数的应用场景,但是对于其它发达国家的语言来说就无能为力了。于是在其上发展出了EASCII(extended ASCII),通过扩展最前面的一位为1来提供多达256个符号编码的支持。可是这样又带来了两个问题:一来即使是256个编码,对于世界范围尤其是像中日这样的汉字国家来说还是远远不够;二来各个国家规定的EASCII编码都不一样,比如对于希腊来说EASCII表示的就是希腊字母,而对于法国来说可能就是某个带有注音符号的字母。这样的背景下,ISO(International Standard Organization,国际标准化组织)设计了ISO/IEC 8859字符集(不包含ASCII),力图一统拉丁语系。其实现的编码表ISO-8859-1(包含ASCII)应用得非常广泛。
GB2312 & GBK & GB18030 & ANSI
本节介绍的是解决EASCII带来的第一个问题的方法。对于中文来说,8位的编码远远不够,于是就会想到用两个8位来表示一个汉字。为了与ASCII码兼容,如果碰到0~127的字符,需要认定为ASCII编码字符。只有当两个大于127的字符连在一起时,才表示一个汉字。前一个字符称为高字节,后一个称为低字节,这样就诞生了GB2312编码。每一个双字节字符就称为一个全角字符,而单字节字符就称为半角字符。再后来,发现编码还是不够用,干脆就允许低字节也使用0~127的字符,反正用高字节就能判断是否是汉字,这样就诞生了GBK(K表示“扩展”)编码。GBK里甚至还包含了日语的假名和俄语字母。GB2312和GBK这两种编码都是单字节(表示ASCII)和双字节(表示汉字)混合使用的编码。我国最新的汉字编码国标是GB18030,这是一种类似下文UTF-8那样的变长编码。
虽然中国解决了中文问题,但是世界各国都搞出了一套自己的编码系统,还是不能轻易相互转化。例如台湾用BIG5,日本用Shift-JIS。要想解决EASCII的第二个问题,还需要另寻他途。Window系统的记事本里,默认编码为ANSI,即根据系统语言的不同,而选用不同的编码。
Unicode & UTF-8
本节说的是解决EASCII带来的第二个问题的方法。ISO带来了一个囊括全球所有文字的编码:Unicode。它最初规定了所有的字符(包括ASCII)都使用两个字节来表示,这个版本称为UCS-2(Universal Multiple-Octet Coded Character Set)或UTF-16。对于ASCII码来说,在它的前面加上00000000作为高字节即可。这样的好处是,由于高低字节可以同时包含0~256,能表示的字符数量就更多了,理论上可以达到256×256=65536个。即使如此,也只能说是基本上够用,要囊括所有文明的文字,还需要更多的字节。目前最多支持4个字节代表一个字符,称为UCS-4或UTF-32,它的最高位规定必须为0,可以表示65536×65536÷2=2147483648个字符(这样是不是统一银河系也够用了)。与此同时,它包含的字符集也在不断的增加,甚至收录了emoji(绘文字),大大增加了文字符号的表现力,看看😂🐔📸🎸🎁🌀🌤🕘,是不是增加了很多乐趣呢。
Unicode就像是“书同文、车同轨”,极大地方便了各国的交流。可是它也有自身的缺点。一个问题是它与各国自身的标准不兼容(例如GB18030),但是这个问题貌似无解,因为各国的标准本来就是排斥的。另一个问题是随着Unicode标准的发展,出现了4个字节的字符。但是当设计Java的时候,是将unicode当做2个字节的定长字符来看待的。这样就导致Java里需要用两个char来表示一个4字节的字符,如emoji(😂=\uD83D\uDE02)。Java平台中的增补字符就是Oracle官方写来专门解决长字节Unicode的。打开链接就会看到一堆的乱码,说明编码问题还真是普遍存在并难以解决的啊。好在还有英文版可供阅读。还有一个问题就是对于英文来说,用高字节为固定值的两个字节来保存数据,就会使原来一个字节的数据量翻倍,对于传输和存储来说都是较大负担。
解决上面这个问题的办法就是UTF-8。它是一种变长的编码方式。如果是ASCII码的字符,就用一个字节表示。否则就在前面增加一个高位字节(但是在8个bit之内)。这回英文符号是满意了,但是中文字符可能就会因为增加的高位字节从Unicode的占用两个字节变成UTF-8的占用三个字节。没有两全其美的事啊!这也是为什么GB2312和GBK今天仍被广泛使用的原因之一,我们也不想增加传输和存储的负担呀。
如果要打开一个文本文件,首先需要知道它的编码。位于文件头的BOM(Byte order mark,字节顺序标记)可以用来标记文件的编码类型。它分为BE(big-endian,大端序)和LE(little-endian,小端序),指的是高字节的位置在前还是在后。但是在类Unix系统中,它很可能因为无法被程序识别而带来一系列问题。所以一般的纯文本文件还是建议保存为不带BOM形式的编码。Window系统的记事本里,如果输入联通保存,便会将其保存为无BOM的GB格式,再次用记事本打开此文件时,因为没有BOM信息,记事本就需要自己推断这个文件的编码是什么。显然window是上这个推断很有问题,误认为是UTF-8格式(可以从文件菜单里的“另存为”看出来)。而mac上默认的文本编辑表现还是不错的。如果用word来打开它,便可以在一系列的编码中,自行寻找合适的编码来打开。如果用记事本另存为UTF-8格式,便不会有问题。Sublime Text可以支持用许多不同的编码来打开或是保存,光是UTF系列的就不少,如下图: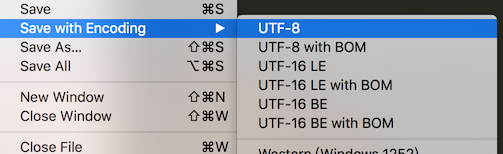
对于Java来说,内部的String编码默认为UTF-16,但如果由于用不着而觉得浪费内存的话,可以在JVM打开-XX:+UseCompressedStrings,就会变成ISO-8859-1了。Intellij IDEA的Preference里,有两个关于encoding的选项: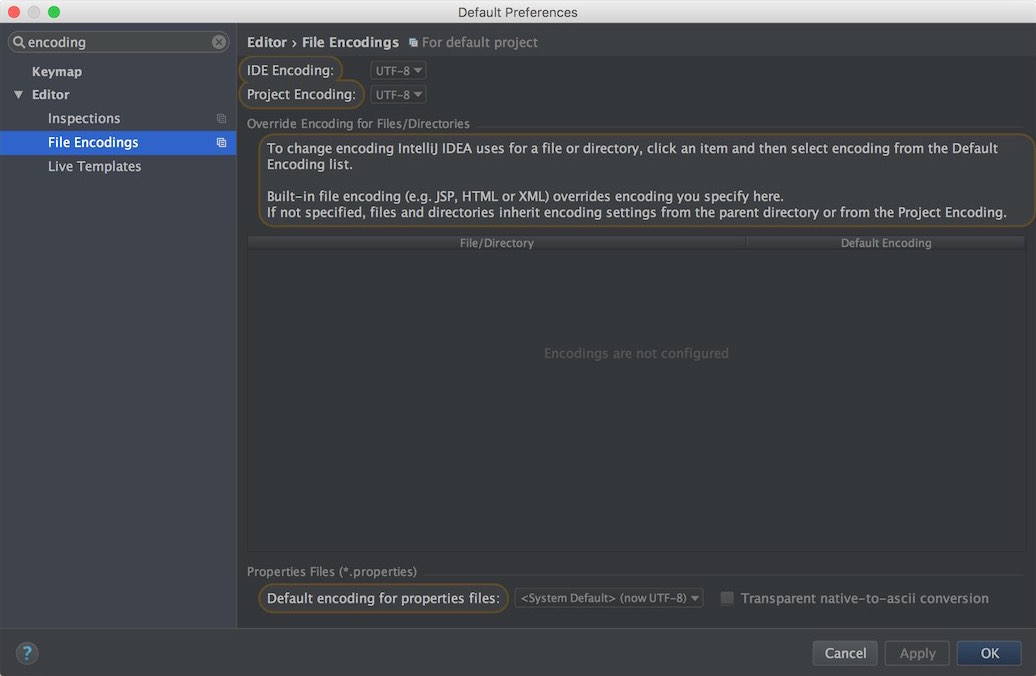
可以通过Project Encoding来指定项目的JVM里String的内部编码,默认为UTF-8。可以通过下面这两个表达式来看到,它们的编码是完全一致的:
Java里可以用Integer.toHexString来看到汉字的unicode编码:
通过下面的语句,可以将字节数组byte[]还原为原先的字符串。如果指定错了编码,就会看到乱码产生啦:
读文件、流也是一样的道理,知道了它们的编码才能正确地读取,否则只好像微软的记事本那样去猜啦。Java还提供了一个小工具native2ascii,可以把本地编码的文件转换为各种格式:
base64 & UTF-7
Base64是一种在网络上传递信息时常见的编码。它相当于是一张64条记录的映射表,键从000000到111111,值就是64个不同的字符。编码时,如果原字符的bit数正好能被6整除,那就查表得到每6个bit所对应的值,合起来就是base64编码的结果。如果不能被6整除,那就在末尾用0补足。每补两个0,就在最终结果的后面加一个=号。所以如果一段数据以等号结尾,那十有八九就是base64编码。Mac或Linux可以用以下命令来进行base64编码及解码:
JavaScript可以用以下命令来进行base64编码及解码:
UTF-7理论上也属于一种base64编码,只不过它的64行映射表不一样罢了。过去的SMTP协议仅能接受7个bit(ASCII)的字符,Unicode无法直接传输。所以通过UTF-7编码的方式,将Unicode字符转换为7个bit以内的字符。UTF-7本身并不是Unicode的标准,现在也已经由于邮件和传输都支持UTF-8而退出历史舞台了。
写到这里感觉得收一下了,不然MD5、SHA什么的都要出来了。对散列、加密有兴趣的童鞋们可以参考我以前写的另一篇文章《证书的那些事儿》。
转义(escaping)
html & url
下面说说转义,不少人都把它与编码混而一谈,以至于它也算作编码的一部分了。从最简单的html聊起吧。在html里,如果只写上一些文本,那当我们用浏览器打开这个html时,就会完完整整地显示这些文本的内容。我们也知道,html里无论输入多少个空格,只会显示一个空格。因为在html里,把空格当成了特殊字符。在这种情况下,如果想要在html里放上空格,就需要对空格编码,也就是大家熟知的 。其中nbsp大名唤作Non-Breaking Space(不换行空格),除了名字以外,它也有自己的编码: 。除了空格,常见的还有代表标签的<和>。完整的html转义可以从这里找到。奇怪的是这么常用的转义,js居然没有原生的函数支持。如果要转义<div>,可以使用下面这条语句来得到<div>:
解码的话,这样做:
如果使用jQuery,思路一致,但是代码可以稍微短一点:
可惜的是上面的函数并不能解决空格和 之间的转换。想要个万能的?也许只好使用replace一个个地慢慢替换了。
想要请求一个html,需要先输入一个url。这里就涉及到了url转义。因为url里可能会有类似?name=ggg这样的参数,所以起码就需要对?和=进行转义。转义之后分别为%3F和%3D,这与ASCII码是相对应的。完整的url编码可以从这里找到。这回js终于有原生的函数支持了:
用encodeURI函数的网址,不会去碰http://,所以编码后还是一个合法的网址。而encodeURIComponent会将一切都进行编码,网址也就不是网址了。不过它很适合将网址作为参数来使用。解码的话,这样做:
在Java里可以用以下语句来完成url的转义:
XML & YAML & JSON & CSV
在这些数据格式中,对xml的转义基本上跟html差不多,这里就不再赘述了。对于yaml来说,规则如下:
- 在一个单引号标注的字符串中,一个单引号需要转义成两个单引号
- 在一个双引号标注的字符串中,大部分符号都需要用反斜杠来转义
- 如果字符串中有控制字符(如
\0、\n等),需要用双引号来标注 - 如果字符串看起来像下面的样子,需要用引号(无所谓哪种)来标注:
true或falsenull或~- 看起来像数字,如
2,14.9,12e7等 - 看起来像日期,如
2014-12-31
完整的规则可以参考yaml规范。
对与json来说,需要转义的字符如下图:
对于csv来说,转义的规则只有两条:
- 如果值里有逗号、换行或是双引号,需要用双引号来标注
- 如果值里有双引号,需要把它转义成两个双引号
""
Java & .NET & JS & SQL
对于大部分的编程语言,例如Java、.NET还有JavaScript,甚至C、GO、Ruby等等来说,通常的转义都是通过反斜杠\来实现的。一般都包括如下几项:
- 退格:
\b - 换行:
\n - 制表符:
\t - 回车:
\r - 换页:
\f - 双引号:
\" - 反斜杠:
\\
不过C和C++支持的16进制\x,在java里不被支持。所以\x61\xd2的这个“懒”字,在java中可以通以下这两个表达式来得到真实的字符:
SQL有些不一样。它从语法层面支持模糊查询,所以即使在完全匹配中使用了%也不需要转义。但是代表字符串的单引号'还是不得不转义成两个单引号''。
后记
以上是关于编码和转义的一些常识,知乎上转的这篇回答,系统地介绍了从ASCII到UTF-8,写得非常赞。平时需要编码和转义的时候,可以使用这个网站在线转换,也挺方便的。
