领域驱动设计DDD
Domain Driven Design(DDD)是Eric Evans于2004在其同名著作里提出的概念,它指明了让软件设计满足理想需求模型的方向。但是建模、设计这种事本来就很抽象,读懂这样的大作也是需要消耗不少脑细胞。本文希望能尽量以简单加实例的方式介绍DDD里的一些常见概念。
简介
什么是领域
《领域驱动设计》书里写的是:用户会把软件程序应用于某个主体区域,这个区域就是软件的领域。简单来说,就认为是公司的某块业务好了。如果领域比较大,可以将其拆分为多个子域(Subdomain),子域包含核心域(Core Domain)和支撑子域(Supporting Subdomain),核心域顾名思义,是最重要的子域,我们应该把关注点集中在它上面;其余的子域都是支撑子域。支撑子域里有一类特殊的用于解决通用问题的子域,称为通用子域(Generic Subdomain),例如用户和权限等。不过这些都是相对而言的,对于消费方来说,他的支撑子域有可能就是你的核心域。个别子域可能会有交集,称为共享内核(Shared Kernel),目的是减少重复,但是仍保持两个独立的上下文。由于不同子域的开发团队可能会同时修改共享内核,所以需要小心并注意沟通。
要DDD做什么
DDD试图解决的是软件的复杂性问题,如果软件比较复杂,或者是预期会很复杂,或者是你不知道,那么都可以开始考虑DDD。否则,由于维系领域模型需要实现大量的封装和隔离,DDD会带来较大的成本。但是,DDD并不是一个笨重的开发过程,它能够和敏捷开发很好地结合起来,另外,DDD也倾向于“测试先行,逐步改进”。
战略建模(Strategic Modeling)
通用语言(Ubiquitous Language)
其实写软件就像是翻译,把领域上的业务需求翻译成软件的各个功能。业务需求来自领域专家(Domain Expert),程序员们需要把领域专家的语言翻译成程序。如果程序员们翻译的时候使用的是自己的语言,而领域专家使用自己的行话,导致术语不一致,就会使得沟通不顺畅,难于消化知识。所以团队需要一种通用语言来进行沟通。这样的通用语言尽量以业务语言为主,而非技术语言。一开始的通用语言可能不尽完美,但它就像是代码一样,经常需要重构。例如:“创建一个订单”就比“插入一条订单数据”更容易让领域专家明白谈话的背景。
限界上下文(Bounded Context)
通用语言里,同一个名词在不同的场景里不一定有相同的意思。比如用户,在推荐好友(可能关注年龄、性别、地域)或是浏览商品(可能关注喜好、历史购买记录)的时候有着不同的含义。所谓的不同的场景,其实就是不同的限界上下文。子域在限界上下文中完成开发。限界上下文主要用来封装通用语言和领域模型,显式地定义了领域模型的边界。不同的限界上下文,都会有一套自己的通用语言。通过这样的划分方式,来让每个限界上下文都尽量保持简单,也算是SRP原则在不同粒度上的一个体现。如果不去做这样的划分,可能最终这个软件就会演变成一个大泥球,或者说是单块系统。尽管如此,对于比较小的业务或项目来说,可能只会有一个限界上下文。现在流行的微服务,很大程度上就是按照限界上下文来划分服务。例如:商品上下文,订单上下文,物流上下文等。当然,如果子域很小,不见得非得微服务化。
不同的限界上下文之间,通过上下文映射图(Context Map)来进行交互。上下文映射图其实就是一个简单的框图,表示限界上下文之间的的映射关系。下面这张图就是一个简单的例子: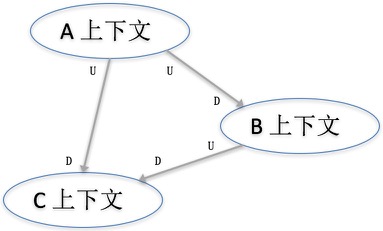
U表示上游(Upstream)的被依赖方,D表示下游(Downstream)的依赖方。由于上下游的限界上下文模型不同,实现时,可以用RPC、Restful、消息机制等集成方式。另外,下游需要防腐层(Anticorruption Layer)来将上游的返回内容翻译为下游的领域模型。如果防腐层过多地使用了各种赋值,从而导致上下游的模型非常类似,那就需要看看是否下游过多地使用了上游的数据,从而导致自己的模型不清晰。
战术建模(Tactical Modeling)
模型
实体(Entity)
所谓领域,反映到代码里就是模型。模型分为实体和值对象两种。实体是有标识(Identity)的,两个拥有相同属性的实体不是相等的,除非它们的标识相等;而不同实体的标识不能相等。例如:某人下了两个相同的订单,里面都购买了相同的商品。这两个订单就是有标识(订单号)的两个实体,虽然内容相同,但它们是两个不同的实体。常用的标识有自增数字、Guid、自然标识(如邮箱、身份证号)等。实体具有生命周期,它们的内容可能在这期间会发生改变,但是标识是永远不会变化的。实体作为领域模型的主体,需要拥有自己的方法,方法名来自于通用语言。通过这些方法来保证自己始终是一致的状态,而非被调用者set来set去。例如:people.runTo(x, y),而非people.setX(x);people.setY(y);
值对象(Value Object)
实体用来表示领域中的一个东西,而值对象只用于描述或度量一个东西。值对象没有任何标识,只要两个值对象的属性相等,那么它们就是相等的。值对象是不可变的,如果要改变值对象的内容,那就重新创建一个值对象。值对象没有生命周期,因为它只是值而已。例如:金额(含数值和货币单位),颜色(含rgb值)等。因为不需要标识,所以它们其实比实体要简单许多。Java里的String类,就具有一个值对象的行为;C#的Struct其实就是一个值对象,不过一般还是会用Class来表示值对象。
不同的领域需求可能会催生不同的建模。例如:考虑一下演出的售票系统。如果需求是对号入座,那么座位就是实体,一旦某张演出票关联了某个座位,那么这个座位就再也不能被其它的演出票所关联了。如果需求是先到先坐,那么座位就是值对象,我们只关心卖了多少张演出票,不要超过座位上限即可,而并不用关心哪个座位被哪张票所关联了。
DDD的一个反模式就是拥有一堆get和set方法的贫血领域对象(Anemic Domain Object)。这样的对象只是一个数据持有器(data holder),而非我们想要的领域模型。值对象和实体一样,都需要有自己的方法。例如:金额值对象,有一个Add的方法,接受一个金额参数,返回一个新的值对象。
实体里可以包含值对象,值对象里也可以包含实体。
领域服务(Domain Service)
有些操作不属于实体或者值对象,那就不用强塞给它们,创建领域服务来提供这些操作吧。留意通用语言,如果里面出现了名词,那一般就是实体或值对象;如果里面出现了动词,那通常就意味着领域服务。例如:支付,这是一个比较明显的业务操作。另外,如果有什么操作会让实体变得臃肿,也可以使用领域服务来解决。但是,不能把所有的东西都堆到领域服务里,过度使用领域服务会导致贫血对象的产生。
据Eric Evans所言,设计良好的领域服务具有以下三个特征:
- 操作不是实体/值对象的一个自然的部分
- 接口根据领域模型的其它元素定义
- 操作无状态
还需要注意的是,不要把领域服务和应用服务混起来了。我们在领域服务里处理业务逻辑,而并不在应用服务里处理。应用服务是领域模型的直接客户,负责处理事务、安全等操作。
领域事件(Domain Event)
《领域驱动设计》一书出版之后,DDD社区并没有停止前进的步伐。领域事件就是在那之后提出来的。领域事件是一个定义了领域专家所关心的事件的对象。当关心的状态由于模型行为而发生改变时,系统将发布领域事件。如果通用语言里出现了:“当……的时候,需要……”通常就意味着一个领域事件。例如:当订单完成支付时,商品需要出库。这里的订单完成支付就预示着一个OrderPaidEvent,里面持有着这个订单的标识。领域事件代表的是已经发生的事,所以命名上通常都使用过去时(如Paid)。对领域事件的处理就像是一个观察者模式,由领域事件的订阅方来决定。订阅方既可以是本地的限界上下文,也可以是外部的限界上下文。
模块(Module)
如果领域模型发展得比较快,很难整体来讨论它,因为太大了。我们可以将模块视为Java中的包或是C#中的命名空间。将模型组织到不同的模块中,可以有效地降低领域的复杂性。模块之间应该是低耦合的,而模块内部应该是高内聚的。模块的名称应该是通用语言的组成部分,反映出领域的深层知识。
生命周期
聚合(Aggregate)
聚合就是一组应该呆在一起的对象,聚合根(Aggregate Root)就是聚合在一起的基础,并提供对这个聚合的操作。聚合除了聚合根以外,还有自己的边界(boundary),即聚合里有什么。例如:一个订单可以有多个订单明细,订单明细不可能脱离订单而存在,而订单也不可能没有订单明细。这种情况下,订单和订单明细就是一个聚合,而订单就是这个聚合的聚合根,订单和订单明细就处于这个聚合的边界之内。如果要变更订单明细,我们需要通过操作聚合根订单来实现,如order.changeItemCount(),而非订单明细自身。另外一个例子:一名客户可以有多个订单,订单不可能脱离客户而存在,而客户却可以没有订单。这种情况下,客户和订单就是不同的两个聚合,一个聚合以客户为聚合根,另一个聚合以订单为聚合根,引用客户的标识。客户里并不引用订单的标识,这样将关联减至最少有助于简化对象的关系网。但是带来的一个麻烦就是如果要查找某位客户的所有订单,就不得不从所有的订单里查,而不能从客户这个聚合里直接获得。最后再举一个多对多的例子:一个班级可以有多名学生,学生可以脱离这个班级而存在,而班级不能没有学生,学生也不能不在班级里。这种情况下,班级和学生也是不同的两个聚合,一个聚合以班级为聚合根,引用学生的标识;另一个聚合以学生为聚合根,引用班级的标识,将多对多转换成两个一对多。
聚合是持久化的一个单位,我们需要保证以聚合为单位的数据一致性。如果聚合太大,那就会导致并发修改困难,多人并发修改同一个聚合里的不同项目,结果就是只有第一个提交的人成功修改,其它人不得不重新刷新聚合才能再次修改。大聚合还会导致性能问题,因为操作实体时会将整个大聚合同时加载进内存。珍爱生命,拒绝大聚合。
聚合根必须是实体而非值对象,因为它需要整体持久化,所以一定会有标识。而聚合根里的各个元素,既可能是实体,也可能是值对象。例如:一个订单(聚合根)一般会有订单明细(实体)和送货地址(值对象)。这些元素里可以有对聚合根的引用,但是不能相互引用。任何对其它元素的操作都必须通过聚合根来进行。聚合根里的标识是全局的,聚合根里的实体标识是聚合里唯一的本地标识,因为对它的访问都是通过聚合根来操作的。聚合根拥有自己独立的生命周期,其实体的生命周期从属于其所属的聚合,值对象因为只是值而已,并没有生命周期。
工厂(Factory)
工厂是生命周期的开始阶段,它可以用来创建复杂的对象或是一整个聚合。复杂对象的创建是领域层的职责,但它并不属于被创建的对象自身的职责。实体和值对象的工厂不太一样,因为值对象是不可变的,所以需要工厂一次性创建一个完整的值对象出来。而实体工厂则可以选择创建之后再补充一些细节。
资源库(Repository)
资源库是生命周期的结束,它封装了基础设施以提供查询和持久化聚合的操作。这样能够让我们始终聚焦于模型,而把对象的存储和访问都委托给资源库来完成。以订单和订单明细的聚合为例,因为一定是通过订单这个聚合根来获取订单明细,所以可以有订单的资源库,但是不能有订单明细的资源库。也就是说,只有聚合才拥有资源库。需要注意的是,资源库并不是数据库的封装,而是领域层与基础设施之间的桥梁。DDD关心的是领域内的模型,而并非是数据库的操作。理想的资源库对客户(而非开发者)隐藏了内部的工作细节,委托基础设施层来干那些脏活,到关系型数据库、NOSQL、甚至内存里读取和存储数据。
参考资料
《领域驱动设计》
《实现领域驱动设计》
《领域驱动设计精简版》 by InfoQ
《Domain Driven Design: A Step by Step Guide》系列
